

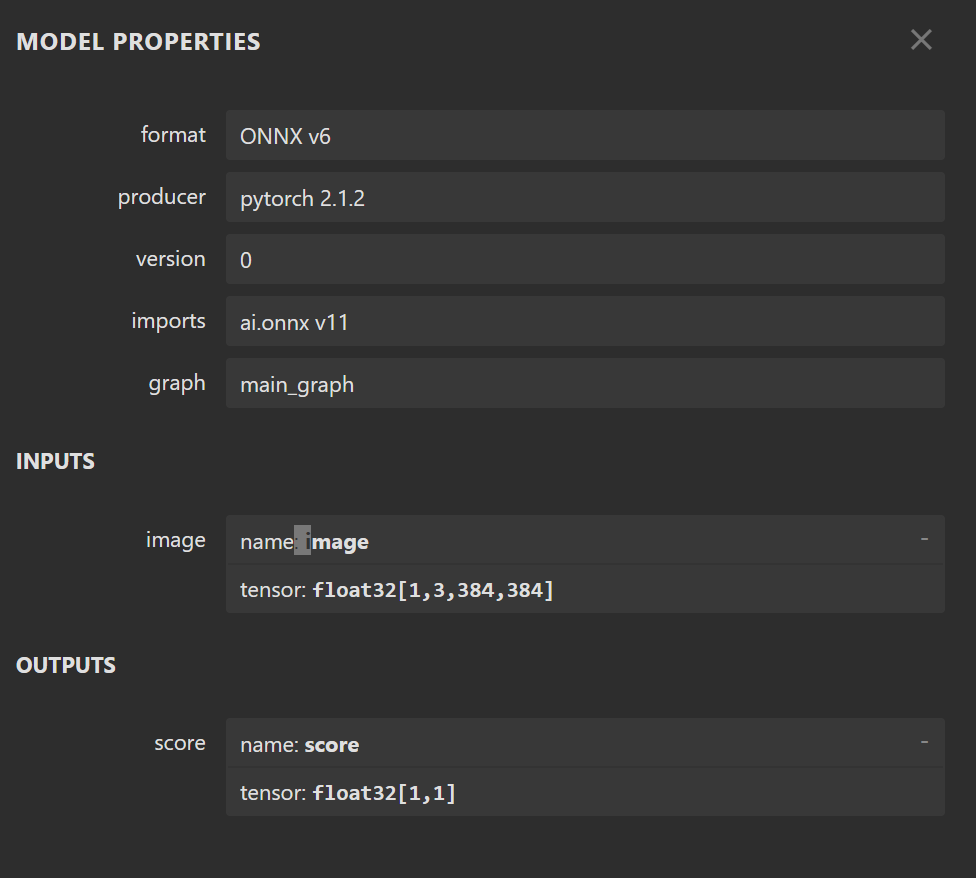
模型轉檔 error

我有一個透過pytorch 訓練的 efficientnetv2s 模型, input size 384*384, model size約80MB,
我在進行下圖的流程轉檔時,在 km.analysis 遇到問題。
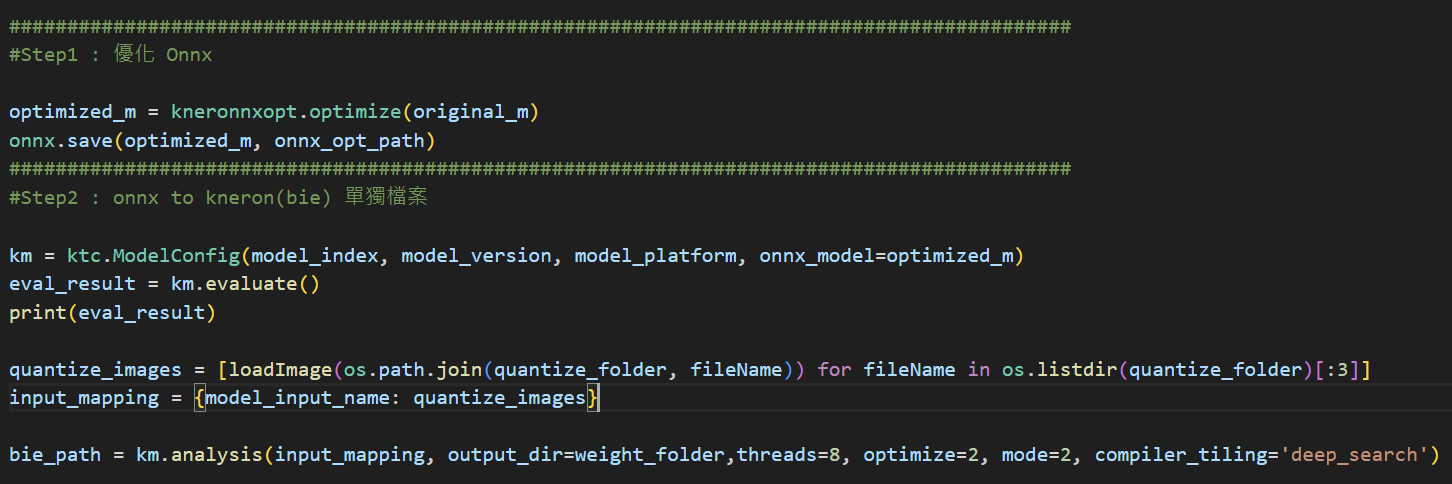
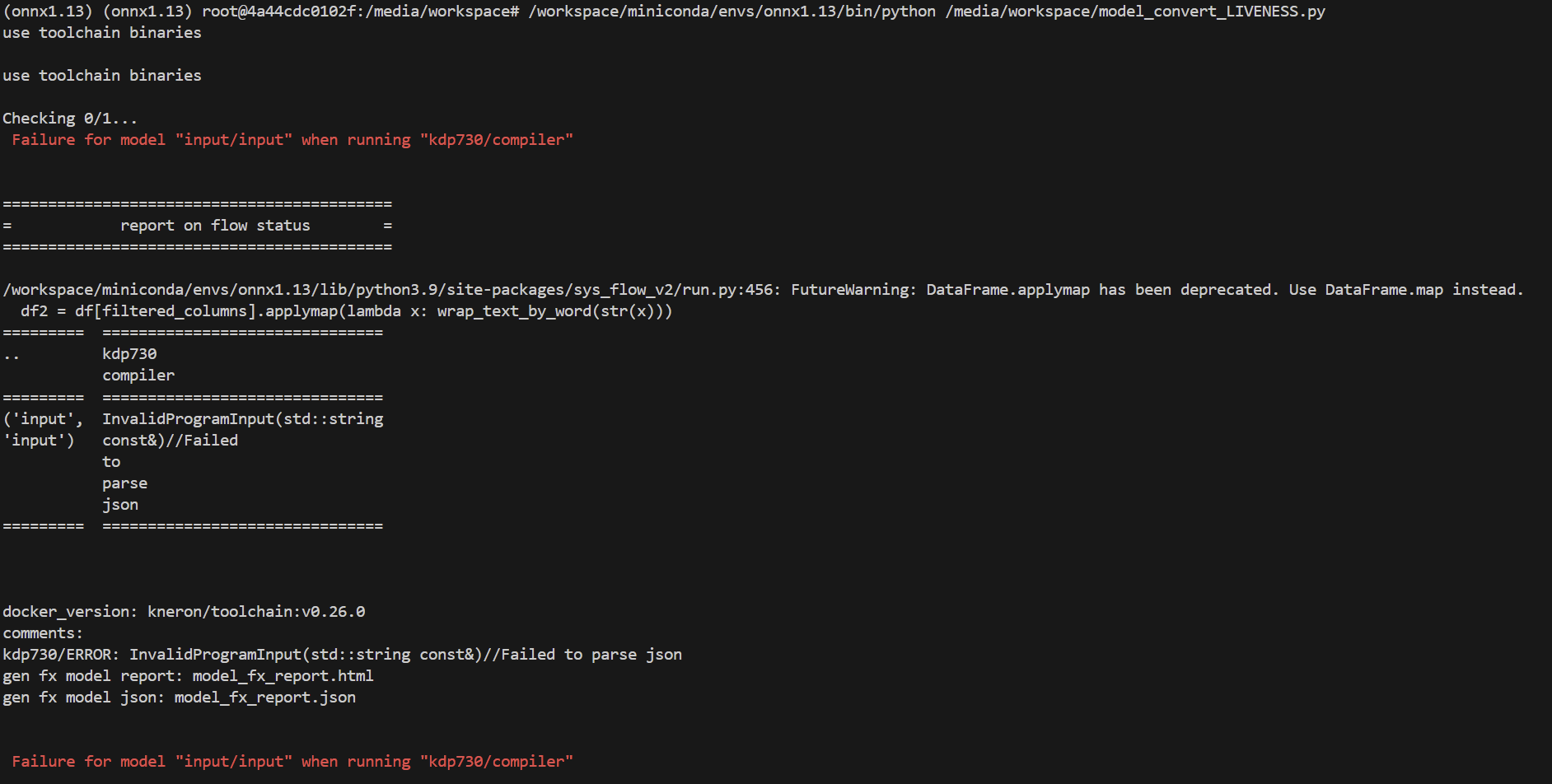
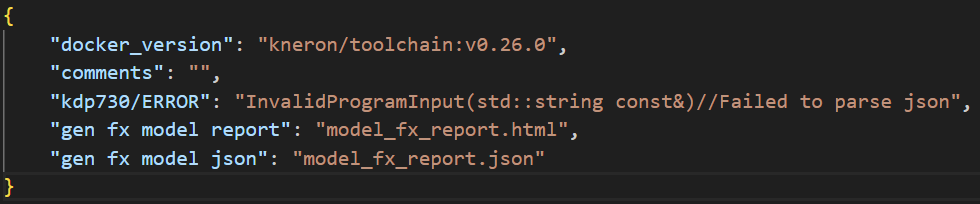
以下是錯誤訊息
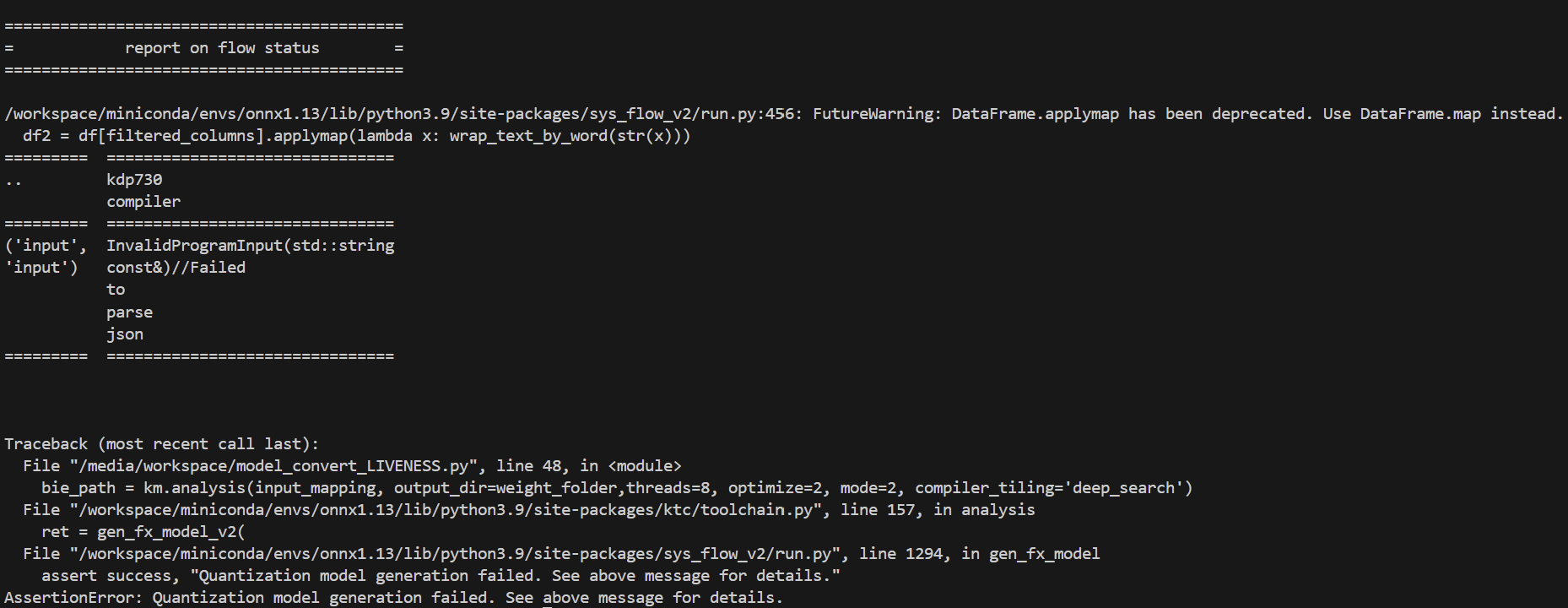
此為model_fx_report.json
請問我可以如何釐清解決問題,謝謝!
The discussion has been closed due to inactivity. To continue with the topic, please feel free to post a new discussion.
Comments
有參考論壇解決方法,刪除description屬性,似乎解決一開始就報錯的問題,但變成卡在分析階段(超過十分鐘沒有變化),僅用三張圖片做量化測試而已,測試過其他模型不需要超過一分鐘,
也沒有任何log可以得知轉檔的狀態。
後續有參考論壇解法,刪除onnx description屬性,
在測試後,會卡在下圖流程超過半小時,(僅測試量化三張圖片,其他模型皆可在一分鐘內完成)
觀察CPU使用量有在變化
您好,
請問一下,可以麻煩您提供onnx模型 (optimize前和optimize後) 和量化時使用的圖片嗎? 謝謝!
Hi Maria,
因為檔案大小超過上傳限制,我透過雲端提供您下載,謝謝
https://drive.google.com/drive/folders/1gUCnt6WPM4L8EmY92wFVcEhvpKPShDjp?usp=sharing
1.有測試不設置 mode & optimize ,使用預設參數,並搭配三張圖片進行量化,可產生後續 nef, 但至少需要10分鐘才能跑完一次測試。
請問有方法可以即時觀察處理進度嗎?
2.使用下列function測試 nef效能,在模擬器需要五到十分鐘才能執行完成,想請問是這個模型太大,導致效果非常不如預期,還是是因為模擬器本身速度就會比較差?
kneron_fixed_output = ktc.kneron_inference(input_data, nef_file='weights/liveness/models_730.nef', input_names=[model_input_name], platform=730)
Hi Louis,
謝謝您提供資料。模型看起來是沒有問題,我們這邊上周也有做測試,也花了很久的時間轉換模型,所以我們現在正在釐清原因。關於處理速度,toolchain沒有辦法即時觀察
以防萬一,也可以請您提供您轉換模型的python script嗎? 謝謝!
Hi Maria ,
謝謝協助
好的 測試檔案會提交於附檔。
另外想請問一下,這個模擬器轉檔的耗費時間與實際在板子運作的時間是成正比的嗎? 就是可能這個模型在板子上運作也會很慢很耗費時間?
因目前還沒辦法實際連接板子做評估(例如 dongle mode),所以想詢問一下可能情況,以利專案後續開發。
Hi Louis,
謝謝您提供檔案,我們現在在檢查,請稍等!
用Kneron toolchain轉檔的耗費時間和實際在板子上運作的時間沒有關係,轉換模型的過程會消耗比較多的時間,也會需要看量化和優化的時間,但是這個過程是一次性的。
要測量板子/dongle inference的速度的話,您可以檢查model_fx_report上面的FPS:
上面寫18.6255,意思是我們的KL730,1次inference這個模型大概會花0.054秒 (1/18.6255)
Hi Louis,
Code裡面的km.analysis()有用deep_search:
它會讓轉換過程變慢,所以我們會建議您先不用deep_search,等到可以成功轉換之後再打開deep_search重新跑一次,結果會是一樣的,FPS會提高。
另外,mode設定為2,會跑csim (用CPU模擬NPU去inference),所以也會讓速度變慢
用ktc.kneron_inference()測試nef也是在跑csim,所以過程會比較慢,不過這個不會影響實際在板子/dongle上inference的速度。
感謝回覆,目前大致問題已釐清,這個模型也可以正常編譯成nef, 只是中間過程比較久而已。