

[Toolchain]若模型在轉換的過程中發生錯誤,該如何自我排除?

現有最新版的toolchain改以python api的方式引導使用者將模型轉換、編譯與推論,但在競賽的文件中還使以傳統各別步驟來完成轉換編譯,在這邊將針對各個步驟的常見錯誤做提醒與說明
Converters http://doc.kneron.com/docs/#toolchain/converters/
1. 模型框架版本是否符合
• ONNX = 1.6, ir_version = 6, opset = 11
• Keras: 2.2.4
• caffe: only support model which can be loaded by Intel Caffe 1.0.
• Tensorflow = 1.15.3 (tensorflow 2 is not supported yet)
• Pytorch = 1.0.0 ~ 1.7.1
• tflite: unquantized TF Lite models
2. 所使用的operator在NPU上是否都有被支援(參考下圖 KL520 NPU的支援列表),像transpose / reshape這類不支援的operator需先移除
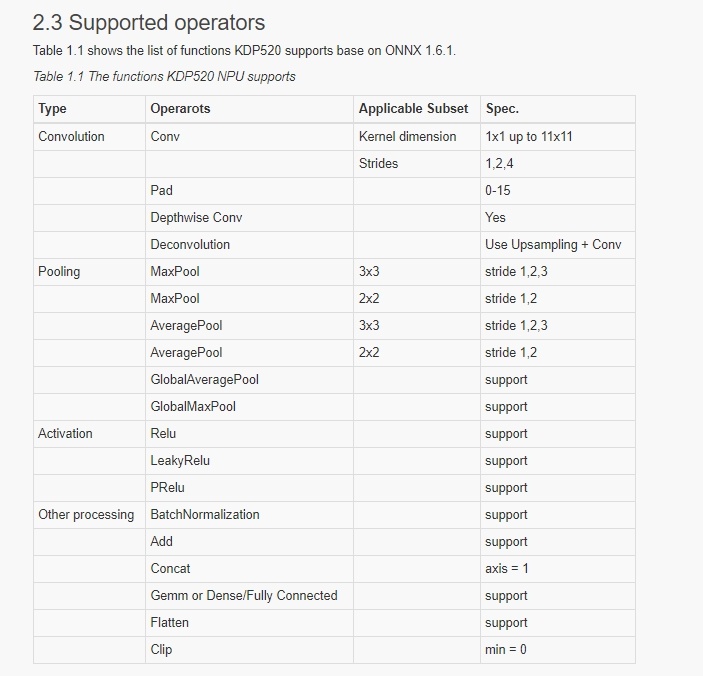
3. 不支援的operator是否為cpu node (目前僅支援 upsample (linear)),又或者是否能改在post process執行? (若不支援的op在模型最後面,則可以先移除,待拿到推論結果後再補做)
4. 是否有執行過ONNX optimization,所有的converter轉換成ONNX後都需要再執行一次 ONNX to ONNX (ONNX optimization)
FpAnalyser , Compiler and IpEvaluator http://doc.kneron.com/docs/#toolchain/command_line/
1. 確認所需要的pre process type (normalization range)
2. 依據pre process range推算radix (7 – ceil(log2 (abs_max))
3. 確認量化用的圖片是否為 training / inference相關的圖片,需要有100張,照片數量過多也可能導致電腦記憶體不足而編譯失敗
4. Input_params.json參數設定是否正確 (FAQ 1. How to configure the input_params.json)
Batch-Compile
1. 在使用batch compile時一定要先透過3.2產生bie後再來執行,無法像舊版直接輸入onnx轉出 bin / nef
2. 520 / 720的fpanalyer與batchcompile需要選定使用,不可以拿compilerIpevaluator_720.sh產生的bie來執行batchCompile_520.py
Comments
您好!想請教一下
謝謝!
Hi Jasmine,
https://stackoverflow.com/questions/36883949/in-tensorflow-get-the-names-of-all-the-tensors-in-a-graph
您好!
我們有試過使用tensorboard查看,但不確定output node是哪個,所以我先選擇了"softmax_cross_entropy_with_logits_sg/Slice_1"
雖然有順利轉出pb檔,轉成onnx檔也沒問題,也將模型轉換成NPU所需架構作最佳化,
但再轉成nef的前置作業時,要產生complier資料夾,執行以下指令
卻出現如下錯誤
請問會是什麼問題呢?
謝謝。
Hi Jasmine,
看起來是因為有不符合預期的 op Cast 與 Slice導致錯誤,我們520不支援cast跟slice, 這應該就是錯誤的原因,還請移除後再重新嘗試一次。
我去察看轉出來的模型很多op 520以及720都不支援,換了別的output node重新轉frozen graph pb檔跑了tensorflow2onnx.py、onnx2onnx.py以及將模型轉換成NPU所需架構作最佳化,也還發現有很多不支援的op,想請問是output node選擇錯誤的問題嗎?
下面是我們的ckpt檔
謝謝!
Hello,
單只有ckpt檔的話可能無法看到你模型的內容,是否能請你提供轉換出來的onnx方便我們評估呢?
onnx檔已上傳至上面的雲端內。
這個是選擇"softmax_cross_entropy_with_logits_sg/Slice_1"當output node,產生如前面所述的錯誤。
謝謝!
@Jasmine
輸出output node時必須要設定正確,
除此之外, 這邊有一點tricky,
由於tensorflow輸出的model要做export時有時候會把常見的operator拆成奇怪的operator,
建議先把模型輸出的tflite後在做轉換會比較容易(tf官方有提供api做轉換, 且會處裡這些奇怪的operator), 再使用tflite轉成onnx.
這邊是我做的一個簡單的測試:
( 這只是個範例, 可能會依照你的需求在裡面做修改, e.g. model input shape, output_node... )
( pb, tflite, onnx 接可以用netron查看模型 )
想請教一下該如何得知"輸出output node"為正確的?
查看了您提供的範例是使用"softmax_cross_entropy_with_logits_sg/Reshape"。
另外,我使用您的範例tflite轉onnx卻有如下錯誤,是有哪裡設定錯了嗎?
謝謝!
您好,下面錯誤訊息的部分已解決,還是想請教一下
謝謝!
關於 "該如何得知"輸出output node"為正確":
可以依照自己對這個模型的了解,以及接下來要做的事 (inference時, 沒轉出來的部分會需要以其他方式實現),
轉出來的model如果沒有你要的operator或與想像的不同(e.g. model size太小), 就是設定錯誤了.
另外可以確認model的graph, model可能有兩個input.
如果設定的output node前面剛好接了其中一個input, 可能導致export出的graph不如預期.
您好,我將轉好的onnx檔(tftarget_opt.onnx)要做IP Evaluator,執行
卻出現下圖錯誤
想請教會是什麼原因?
有試著將原本的模型去cut node產生tftargetcut_v2_opt.onnx,做IP Evaluator也還是出現與上圖一樣的錯誤。
謝謝。
@Jasmine
您提供的指令(compilerIpevaluator_720.sh) 與 圖片中的指令(fpAnalyserBatchCompile_720.py)貌似不太一樣, 您可能要在再確認一下.
我這邊嘗試使用 tftargetcut_v2_opt 做 fpAnalyserBatchCompile_720.py 與 compilerIpevaluator_720.sh 都可以正常執行.
我的tool chain版本: v0.15.4
我input_param.json ( fpAnalyserCompilerIpevaluator_720.py 所要求的參數檔) (測試用, 實際必須依照您的需求做修改):
如果還是會有一樣的錯誤, 再麻煩提供您的 input_params.json 與 tool chain版本, 方便我們確認原因,
謝謝!
您好,我的tool chain版本為v0.15.4。
我使用您的input_params也還是會有一樣的錯誤。
下面是我tftargetcut_v2_opt.onnx的input_params.json。
另外抱歉更正一下,我跑
出現的錯為
我查看workspace/.tmp 內的確是沒有cpu_io_info.json。
但是卻有產生 compiler 資料夾,裡面也有檔案。
所以我就嘗識跑下一步
就出現之前圖的錯誤。
我之前有跑過耐能給的範例(LittleNet)是可以正確執行指令產生nef檔的。(但執行compilerIpevaluator_720.sh的時候一樣會顯示"cp: cannot stat '/workspace/.tmp/cpu_io_info.json': No such file or directory ",所以我猜想第一個錯誤應該是不影響的?)
再麻煩您,謝謝!
@Jasmine
Hi Jasmine,
我們使用您提供tftargetcut_v2_opt.onnx的input_params.json執行以下指令是可以正確產生nef檔。
這邊幫您回答您的問題
我之前有跑過耐能給的範例(LittleNet)是可以正確執行指令產生nef檔的。(但執行compilerIpevaluator_720.sh的時候一樣會顯示"cp: cannot stat '/workspace/.tmp/cpu_io_info.json': No such file or directory ",所以我猜想第一個錯誤應該是不影響的?)1.執行以下指令
此步驟是為了測試模型結構是否可以被ToolChain採用並估計性能,所以如果出現 "cp: cannot stat '/workspace/.tmp/cpu_io_info.json': No such file or directory " 是不並會影響後續的指令產生nef檔,因您使用的platform為720,所以您在此步驟成功執行的結果會在 /data1/compiler/ 下產生 ProfileResult.txt。
2.執行以下指令,產生Bie檔,且可以往下繼續執行,成功產生nef檔。
不知道您那邊是否是在 Windows Docker 環境下執行 Kneron 的 Toolchain?
我們會建議您在 Kneron 提供的 VM ubuntu Linux環境下使用 Kneron Linux Toolchain,或者是在您電腦上的 Linux環境下使用 Kneron Linux Toolchain。
這裡有提供 Kneron VM ubuntu 方便給您使用 Kneron Linux Toolchain : https://www.kneron.com/tw/support/developers/
您好,沒錯我是在Windows Docker 環境下執行 Kneron 的 Toolchain。
我的電腦是windows10,照document建議的使用docker with wsl2。
謝謝您的建議,我想滿大可能是我電腦RAM的問題,我看我的RAM使用情況vmmem佔很大一部分,沒跑指令的時候就佔一半以上了,上網找好像是docker 的部分,我再使用Kneron VM ubuntu試試看,謝謝您!
另外想請教一下KL720做inference的部分,若是使用semantic segmentation的模型放入KL720內,該如何修改host_lib的python檔去做inference呢?因為我看host_lib內的範例都是object detection的。
還是host_lib內的py檔都沒辦法適用於semantic segmentation的模型,要使用其他方法才能去做inference?謝謝!
Hi Jasmine,
一個完整的模型應用會包含
若你已經有完整個GPU應用流程,則可將 步驟2的inference改在KL720上執行,建議可以使用最新的PLUS (新架構的host_lib)來做推論,可參考文件中的generic inference的各種api來發送圖片與收結果 http://doc.kneron.com/docs/#plus/api_reference_1.2.x/kp_inference.h/
另外,因為這篇討論主要是與模型相關,若有更多有關KL720的問題,還請到KL720專區發起新的討論。
了解,謝謝您!