

[LEGACY][v0.12][Example][Keras][KL520] How to convert and compile tiny-yolo-v3 from github project

*** WARNING ***
This is the tutorial for toolchain version v0.12, might not fit the usage of latest version,
please check your toolchain version first.
Hello!
Converting and compiling a model is a little complicate,
here we provide a step by step example to compile a tiny-yolo-v3 from a keras-based opensource project (https://github.com/qqwweee/keras-yolo3.git).
Step 1: Run docker and mount a folder into docker as "/data1"
docker run --rm -it -v /C/Users/eric.wu/Desktop/docker_mount:/data1 kneron/toolchain:520

Step 2: clone yolo project from github
cd /data1 git clone https://github.com/qqwweee/keras-yolo3.git
Step 3: download model weights of tiny-yolo-v3
wget https://pjreddie.com/media/files/yolov3-tiny.weights
Step 4: save weight and model architecture into one h5 file
this project provide us a script to convert the weights file
python convert.py yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny-weights.h5
Step 5: modified input shape information for h5 model
The downloaded h5 weights file is not acceptable for ONNX_Converter and toolchain.
we need to do a simple modification to the h5 file.
In order to achieve this mission, we leverage the code already in the project, train.py, and do simple modified:
- remove training code
- remove redundant layer
- set the model input size
- modified the loaded anchor and classes information file (2021/03/29 Update)
- save loaded mode
the modified example shows in export_tiny.py, you can download from the link bellow,
put the export_tiny.py into root folder of keras-yolo3, then do
python export_tiny.py
then, tiny_yolov3_wo_lambda.h5 should be generated
Step 6: convert h5 file to onnx
Now, we can convert the h5 model directly by ONNX_Converter.
python /workspace/libs/ONNX_Convertor/keras-onnx/generate_onnx.py ./tiny_yolov3_wo_lambda.h5 -o ./tiny_yolov3_wo_lambda.onnx
tiny_yolov3_wo_lambda.onnx should be generated in the same folder.
Step 7: onnx optimization
Kneron-toolchain need specific onnx format, and there might be some operator could be optimized for kl520 and toolchain. ONNX_Converter provide script to help us doing that.
python /workspace/libs/ONNX_Convertor/optimizer_scripts/onnx2onnx.py ./tiny_yolov3_wo_lambda.onnx --add-bn
(*note) --add-bn flag could make toolchain work better while doing quantization.
the optimized onnx model will be saved as tiny_yolov3_wo_lambda_polished.onnx
Step 8: quantization and compiling
follow the document in Chapter 3:
Kneron toolchain need input_param.json and batch_input_params.json
(*note) have to check the data pre-process method in the project, here is what I found:
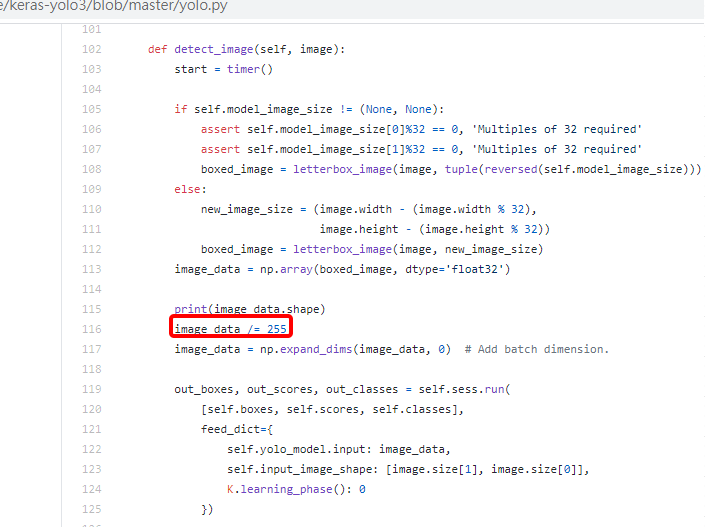
in input_param.json, we need to choose proper pre-process method. Or might got bad quantization result.
Here is my input_param.json:
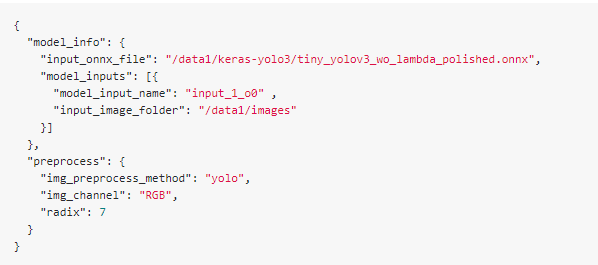
and my batch_input_params.json:
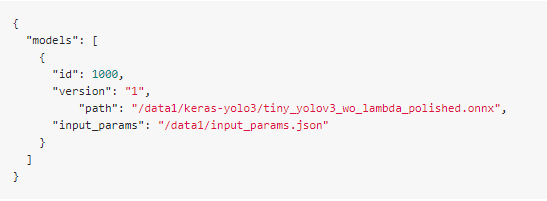
then do quantization and compiling,
python /workspace/scripts/fpAnalyserBatchCompile_520.py -c /data1/batch_input_params.json
script will generate a folder "batch_compile", the models_520.nef in the folde is the final compiled model
Hope this article could help, thanks for watching.
If there is anything wrong or not clear, feel free to discuss bellow.
Comments
我照著以上的流程,出現以下錯誤
Could you provide your .onnx file, input_param.json, and batch_input_params.json?
I guess there is something wrong with your input onnx.
謝謝
Hey Eric,
I followed the tutorial. When going through ioinfo.txt, I noticed the upsampling layer has a "C" next to it. From reading the "Toolchain 520 manual", I came across the following line under FAQ 7:
If you find the cpu node in
temp_X_ioinfo.csv, whose format isc,\**,**”`, you need to implement and register this function in SDK.I think I need to do the above. Where can I find the resource to do that. Also do you have an example that would be easy to follow? I have attached the final ONNX that was generated and the ioinfo.txt file.
Thanks!
Hi @劉峻宇 :
I tried your model and parameters,
after I add a "/" at the "input_onnx_file" in input_param.json, I can compile your onnx sucessfully.
but I think this is not the reason you got the error message you provided.
I guess you put too many images in "/data1/images". I reproduce your error with 500 images in /data1/images.
This is a known issue. I recommend you can try less image.
By the way, I toolchain version I tried is toolchain:520_v0.12.0
Hi @Raef Youssef ,
For the cpu node implementation,
Sorry, I don't know the detail about this.
Someone who know this part might reply this here.
But for the upsampling layer,
The upsampling layer is already implemented in sdk as a cpu node.
You don't need to implement it yourself.
Hi Eric
I followed your suggestion, but the same error still appeared.
Is there a prescribed format for images?
I only have 10 images.
I use the same toolchain as you.
Hi WenTzu,
What kind of image format are you using? General format like jpg and png are usable.
Or could you post your json setting and onnx to clarify the issue?
I've been having issues post-processing the output of the network. The output dimensions of 1x100x13x13 and 1x100x26x26 do not make sense. If the network was trained on VOC then the output tensor should be 1x[(5+20)*3]x13x13 = 1x75x13x13. If trained on COCO then the output should be 1x255x13x13. This output mismatch is evident from the following errors
Can someone please explain the output mismatch and why does the script "export.py" replace the last two layers?
Hi @Raef Youssef,
I found there is a mistake in the export_tiny.py, we have to change the anchor and classes information file:
Sorry about that, I have already updated the export_tiny.py (as export_tiny_20210309_update.zip).
here we convert the original model with 80 classes and 6 anchors. The output shape should be 1x255x13x13 and 1x255x26x26
Hi all,
I found some wrong description in the article, and have some modification. Please check it if you are interest.
By the way,
There is a builtin yolo post-process example in our host_lib (http://doc.kneron.com/docs/#520_1.4.0.0/getting_start_520_kdp2/)
we can check the detection result of our tiny-yolo on kl520 dongle easily with the following example:
Note: model id 1000 comes from "batch_input_params.json" in step8.
I got the following message after run the example:
we can see the bounding box result in the "./ex_kdp2_generic_inference_raw.bmp".
it looks like this:
Hi Eric,
Hi Ic.Wang,
For the "/data1/images"
I lost my calibration data in this case, so I do that again with the following dataset. It's still work. The dataset is picked from VOC 2012 validation set (50 images).
For KL720,
Yes, you should do that.
And acctually it's for toolchain version v0.12, If you are using the latest toolchain (v0.13), you should change
"python /workspace/scripts/fpAnalyserBatchCompile_720.py -c /data1/batch_input_params.json"
to
"python /workspace/scripts/batchCompile_520.py -c /data1/batch_input_params.json"
please check the latest toolchain document for the further usage
For your uploaded model,
It's correct. I can compile your model with voc_data50, and got correct output bounding box on kl520.
thanks!